Quick Start#
Installation#
Using pip:
pip install dplutils
Using docker:
docker pull ghcr.io/ssec-jhu/dplutils:latest
Define Pipeline#
A pipeline is defined as a list of tasks to be executed in order from left to right. The work unit of each task is represented as a function with the signature:
def task_function(input_df: pandas.DataFrame, **kwargs) -> pandas.DataFrame:
...
The input dataframe represents a batch of data to be processed in each task unit in order – with distinct batches possibly running in parallel – producing the modified output dataframe batch. The contents of the dataframe are always workload specific, but often will represent a set of independent units.
Each task function must be wrapped in a PipelineTask object that
contains configuration for how the executor should execute the task, such as resource requirements (e.g. number of CPUs,
GPUs, custom resources) and keyword arguments. A pipeline is thus a list of such tasks.
As an example, lets create a pipeline to generate and sort lists of random numbers greater than some number. Here is what the pipeline task graph looks like:
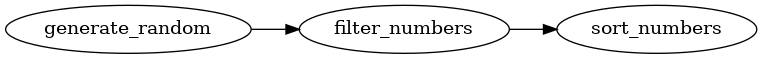
The task definitions and pipeline might look like:
def generate_random(indf, samples = 10):
out = pd.DataFrame({'seq': range(samples)})
out['batch_id'] = indf['batch_id'].iloc[0]
return out.assign(generated = [np.random.randint(0, 10, 100) for i in range(samples)])
def filter_numbers(indf, threshold = 5):
return indf.assign(filtered = indf['generated'].apply(lambda x: x[x > threshold]))
def sort_numbers(indf):
return indf.assign(sorted = indf['filtered'].apply(np.sort))
pipeline = [
PipelineTask('generate', generate_random),
PipelineTask('filter', filter_numbers),
PipelineTask('sort', sort_numbers),
]
Execute Pipeline#
The pipeline on its own isn’t capable of executing anything, it is just a definition of what should be done and the
requirements to do it. This is where implementations of
PipelineExecutor come in. They are responsible for taking the
pipeline graph and coordinating its execution across whatever resources exist, typically in parallel on a cluster of
machines.
The job of the executor is to turn a pipeline definition into a set of pandas dataframes, either materialized in memory
(run) or on disk
(writeto). Presently this package provides a concrete
implementation of the PipelineExecutor using Ray as the distributed execution engine (see
RayDataPipelineExecutor)
For our example, we could execute the pipeline as follows:
pl = RayDataPipelineExecutor(pipeline, 10)
for batch in pl.run():
...
This streams batches in the for loop as dataframes in memory, with which we can do whatever final processing we want. Each batch would look something like:
batch_id generated filtered sorted
seq
0 0 [4, 7, 4, 3, 6, ... [7, 6, 7, 7, 6, ... [6, 6, 6, 6, 6, ...
1 0 [7, 1, 2, 6, 9, ... [7, 6, 9, 8, 8, ... [6, 6, 6, 6, 6, ...
2 0 [4, 2, 1, 2, 1, ... [7, 9, 8, 8, 6, ... [6, 6, 6, 6, 6, ...
3 0 [1, 3, 9, 8, 1, ... [9, 8, 9, 7, 8, ... [6, 6, 6, 6, 6, ...
4 0 [7, 3, 5, 7, 1, ... [7, 7, 6, 8, 6, ... [6, 6, 6, 6, 6, ...
5 0 [9, 8, 6, 6, 0, ... [9, 8, 6, 6, 9, ... [6, 6, 6, 6, 6, ...
6 0 [6, 3, 6, 4, 2, ... [6, 6, 8, 9, 6, ... [6, 6, 6, 6, 6, ...
7 0 [9, 2, 4, 5, 1, ... [9, 7, 8, 6, 9, ... [6, 6, 6, 6, 6, ...
8 0 [1, 6, 0, 4, 3, ... [6, 7, 9, 6, 8, ... [6, 6, 6, 6, 6, ...
9 0 [8, 6, 0, 2, 1, ... [8, 6, 7, 6, 6, ... [6, 6, 6, 6, 6, ...
To write the results of the pipeline out as they become available:
pl.writeto('path/to/dir')
which will write one parquet file per batch to the specified directory, prefixed by the pipeline run_id() and a
sequence number in as-completed order.
Learn More#
The example above did not include topics such as task resource requirements (see X), runtime pipeline configuration (see X), pipeline context (see X), or observability features provided by this package (see X). For comprehensive usage information see Usage.